I’m building a reading app for Spanish learners. You open a story, tap any word, and a card shows the English meaning, a short grammar note, and how to pronounce it. The hard part isn’t the cards. It’s deciding what counts as one tap.
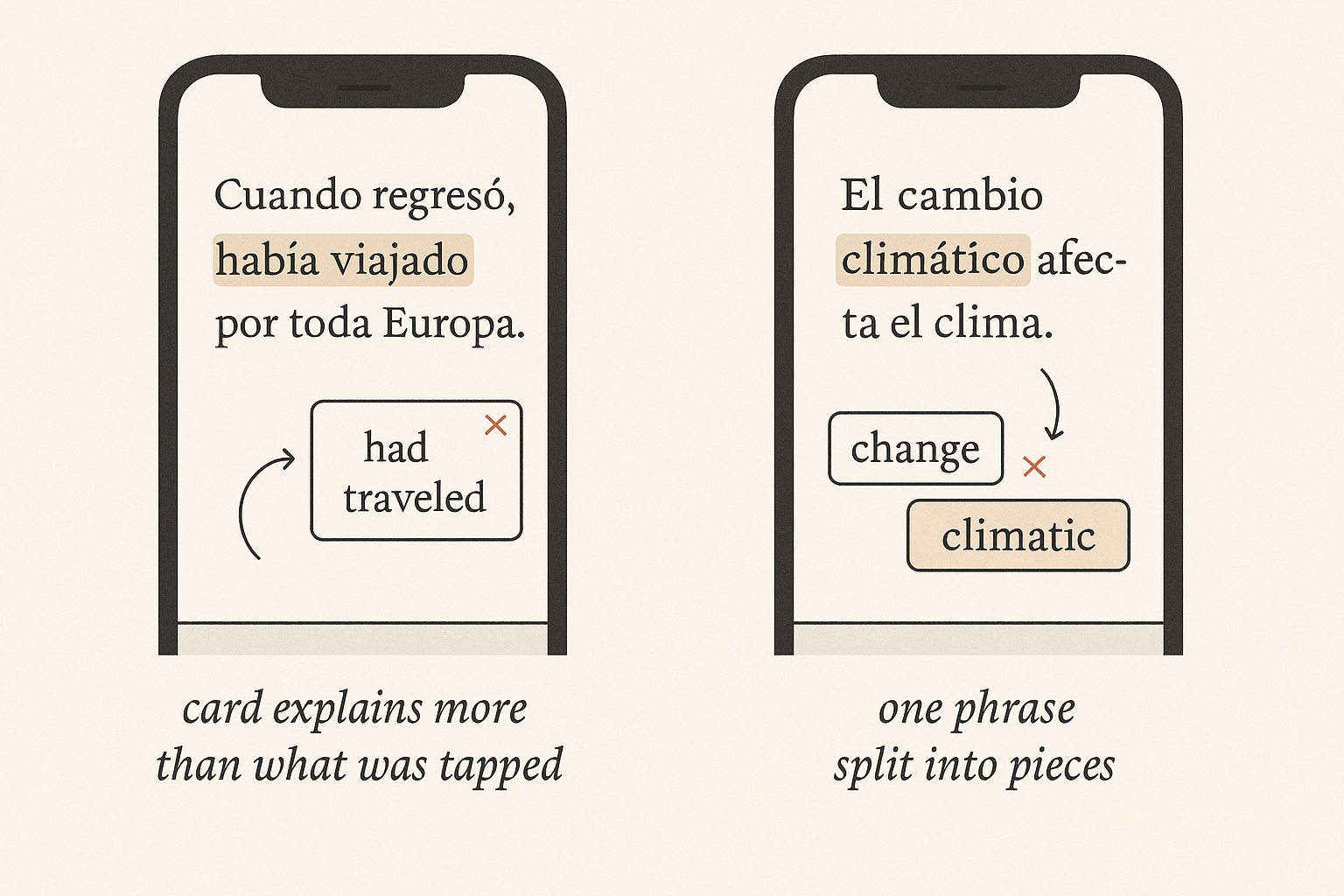
“Se lo dije” is three written words and one thought. “Había viajado” is two written words, but only the first one is what a learner usually wants explained. “Cambio climático” is two words that mean one thing. Get those boundaries wrong and the app feels broken even when every card, read alone, is correct.
I built the first version of this tap-grouping logic the way most people would in 2026: hand the Spanish text to an LLM and let it figure everything out. That was the mistake.
The bug that gave it away
A teacher testing the app tapped “había” inside “había viajado.” The card said “had traveled,” which is the meaning of both words together, not the one he tapped. Same session, he tapped “cambio climático” and got two separate cards, “change” and “climatic,” when it should have been one unit for “climate change.” Two opposite-looking failures, fifteen seconds apart.
I’d spent too long patching these one sentence at a time. Whenever a teacher flagged a case, I’d add another rule for that specific phrase or that specific verb form. The list of patches kept getting longer without the app getting any more predictable. New stories surfaced new versions of the same problem, and the rules I’d written for the last story rarely helped with the next one.
The first version, and what was wrong with it
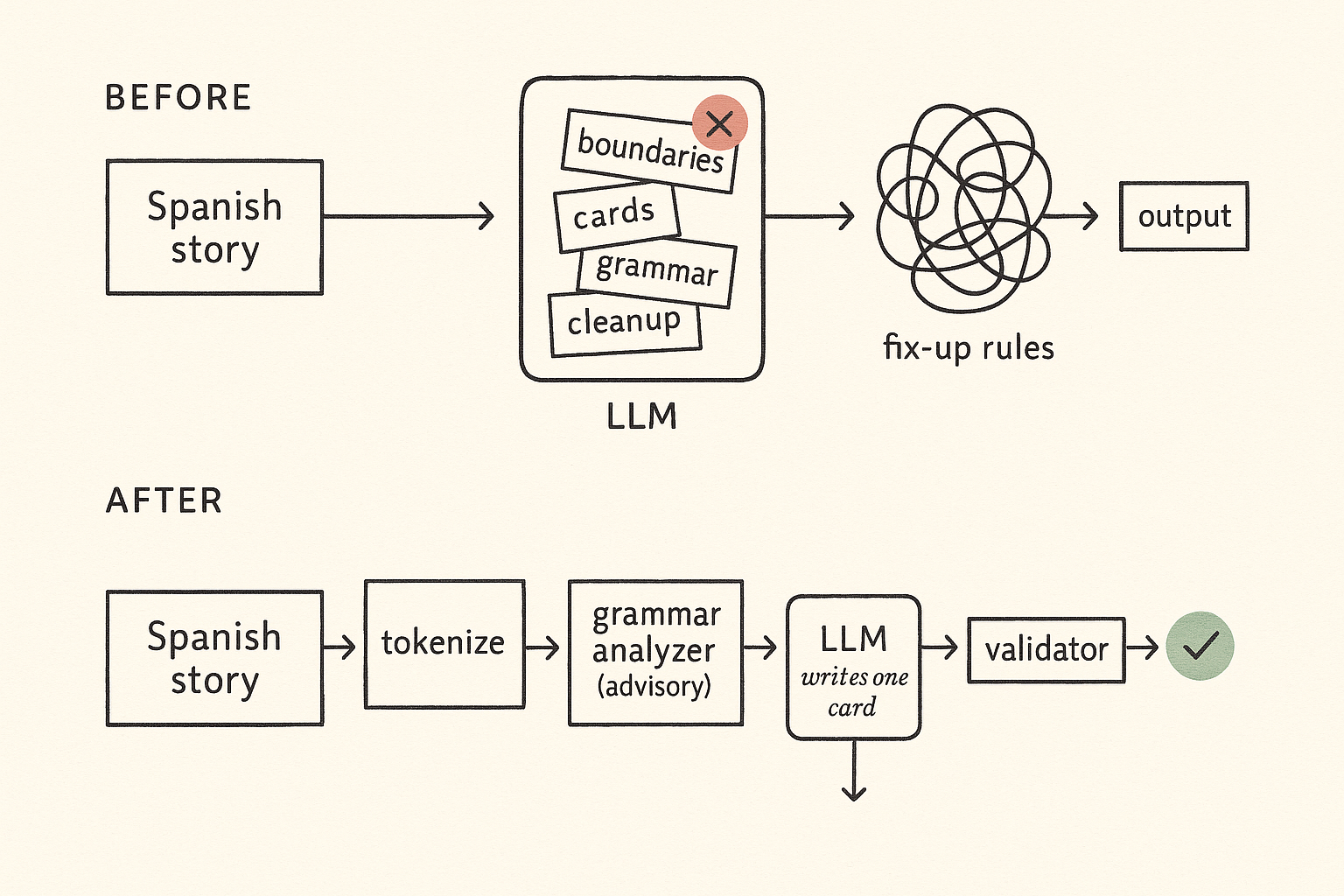
The original pipeline sent the whole Spanish story to an LLM and asked it to do four things at once: group the words into tappable units, write the card for each one, label the grammar, and clean up its own output. A pile of hand-written rules ran afterward to catch the obvious mistakes.
The appeal was that LLMs are good with language and you can describe the whole job to one in a paragraph. The behavior in the happy case looked impressive enough that the failures felt like edge cases I could chip away at.
Two things kept breaking in a systematic way.
The model wasn’t consistent about boundaries. The same phrase in two different stories would be grouped differently for no reason I could explain to the teacher. Sometimes “estaba leyendo” was one unit, sometimes two. I couldn’t promise behavior because I couldn’t reproduce it.
The card text disagreed with the phrase it was supposedly explaining, and there was no place in the pipeline to notice. The model produced the phrase and the card in the same step, so by the time I had the output, the only check I could write was “does this look right,” which is the kind of check that scales to about one paragraph.
The reframe
Two different kinds of decision were tangled together inside one model call.
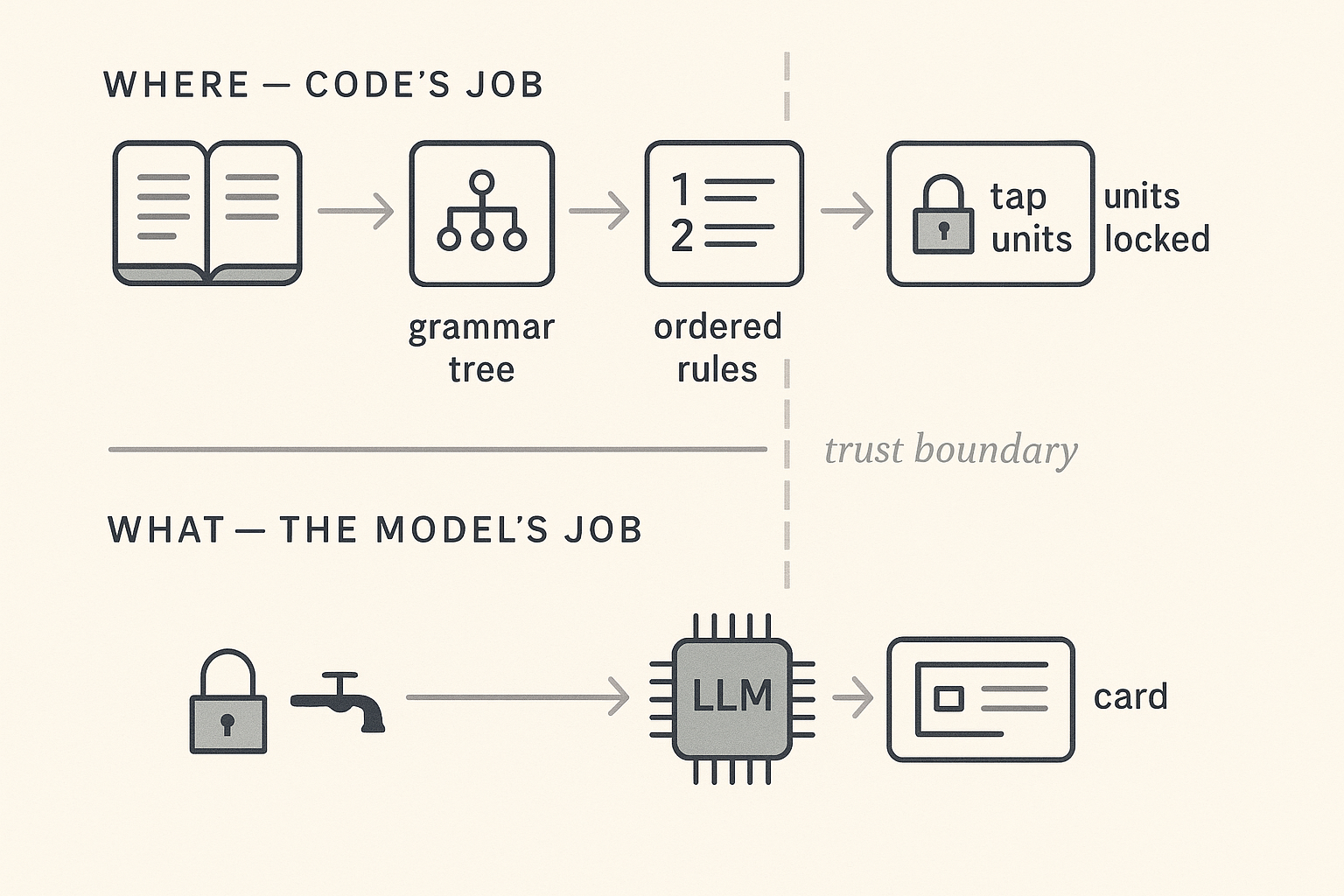
The first kind is structural. Where does one tap end and the next begin? This needs a single right answer for a given input, the same answer every time, and a reason you can point to when a teacher asks why.
The second kind is content. Given one specific Spanish phrase, what’s the clearest short English explanation for a learner at this level? This is open-ended. Two good writers would produce different cards and both would be fine.
LLMs are good at the content kind. They are not bad at the structural kind in any absolute sense, but they’re bad at it in the ways that matter here: you can’t reproduce the answer, you can’t audit it, and you can’t constrain it to a rule a teacher would agree with.
Structural decisions belong in code you can read top to bottom: a dictionary of known phrases, a grammar parser that tells you which words attach to which, and an ordered list of rules with names. Once those decisions are made and locked, you can give the model one phrase at a time and ask it to write a card for that phrase only. It can’t reach across a boundary it never saw.
What the new pipeline actually does
Five steps, in order.
First, split the visible text into the smallest reasonable pieces, mostly individual words plus punctuation. This is the unit the rest of the system reasons about.
Second, run an off-the-shelf Spanish grammar analyzer over the text. It returns part of speech, dictionary form, and which words grammatically depend on which. The output is advice. Nothing downstream is required to follow it; it’s just better-informed input for the rules in the next step.
Third, run an ordered list of rules against that result. Known fixed expressions like “cambio climático” collapse into a single unit. Compound tenses like “había viajado” stay as two separate units but get marked as related, so the card for “había” knows it’s the auxiliary of a participle next to it and can explain itself accordingly. Pronouns stuck onto verbs, like “dímelo,” get split visually back into “di,” “me,” “lo.” Each rule has a name, a category from the teacher’s reference document, and a test case.
Fourth, lock the result. Nothing later is allowed to merge, split, or move a tap unit.
Fifth, generate cards. For each locked unit, call the LLM with that unit, its grammar features, and a small amount of surrounding context for disambiguation. The model writes one card. A validator checks the card against the phrase: if it claims a meaning the phrase can’t carry (translating the neighbor, glossing a finite verb as an infinitive, treating a piece of a proper name as a standalone word), the system either retries with a tighter prompt or falls back to a curated dictionary entry.
The output is a saved artifact that records, for every tap on screen, which rule put the boundary there, what evidence the rule used, what the card said, and where the card text came from. When a teacher reports a bug now, the answer is a row in that record, not a guess.
What changed in practice
Per-sentence patches stopped accumulating. A new story doesn’t introduce new boundary glitches unless it contains a category we haven’t written a rule for yet, and that’s a different, fixable problem with a clear shape.
We can write hand-labeled test cases (for this paragraph these tap units must exist, these must not) and run them on every change. The test suite catches regressions before a teacher does.
LLM cost dropped because we stopped sending full stories and started sending single locked phrases. Most cards now consume a fraction of the tokens the old pipeline used.
Bad cards still happen, but the validator catches the failure mode teachers noticed most: cards that claim more meaning than the tapped phrase actually carries.
And when a teacher asks why a specific tap behaves a specific way, I can answer in one sentence instead of opening a debugger.
The part that generalizes
If you’re building with an LLM and your bug list keeps growing one example at a time, check whether you’ve asked the model to make a structural decision and a content decision in the same call.
Structural meaning: where does one thing end and the next begin, which item is which, which schema field does this belong to, what type is this.
Content meaning: write this, summarize that, explain this in simple words, name this in a way a person would like.
Pull the structural decisions into code, even if the code is unglamorous lookup tables and ordered rules with names. Hand the model the narrowest input that lets it do the content job. Validate its output against the input you gave it, not against your sense of whether it sounds right. You’ll write more code and call the model less, and the system will stop surprising you.
The principle is small and the work is not. Most of what I rewrote was code that doesn’t sound impressive in a blog post: a dictionary file, a list of named rules, a validator. But that’s where the leverage was. The LLM is still doing the part it’s uniquely good at. It’s just doing it inside walls now.